Understanding Robustness of Transformers for Image Classification
Published:
- 论文链接:https://arxiv.org/abs/2103.14586
- 会议: ICCV(2021)
- Keywords: CNN, Robustness, VIT, ResNet
Abstract
该文章从各个角度对Transformer 架构进行鲁棒性分析。
1. Introduction
首先声明 CNN 的 property of spatial locality and translation invariance mapping (空间局限性和平移不变性映射),以及 CNN 已经广泛应用于计算机视觉的相关任务。
接着,引出 Transformer 架构,并引出本篇文章的主角 Visual Transformer(ViT);再然后,说明本篇文章的具体内容:就它们对输入扰动和模型参数本身的鲁棒性而言,试图更好地理解纯粹基于注意力机制结构的行为,并建立对这些模型的理解,以与卷积的知识相对应。
本篇文章的主要贡献:
- 验证在不同数据集上预训练的不同规模的ViT模型的稳健性,并将它们与相应的ResNet基线进行比较。
- 验证了输入扰动后的模型鲁棒性,并发现在足够大的数据集上预训练的 ViT 至少与 ResNet 一样鲁棒
- 验证了模型扰动的鲁棒性,并发现 ViT 对几乎任何单一层的去除都是鲁棒的,而且以后的层只对单个补丁的表示提供有限的更新,但专注于整合 CLS token
2. Preliminaries
2.1 Transformer
提出 Transformer 架构的论文如下,
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, pages 6000–6010, 2017.
Vision Transformer: 与基础的 Transformer 架构的关键区别在图像预处理层,详细论文如下,
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
2.2 Model Variants
本篇文章中对比所使用的模型如下,

3. Robustness to Input Perturbations
这一部分,作者比较了 Transformer 与 ResNets 对输入扰动的鲁棒性。
3.1 Natural Corruptions
用于测试的数据集:ImageNet-C,括15种由算法生成的错误,分为4类:“噪音”、“模糊”、“天气”和“数字”。每种衰退类型有五个严重级别,导致75种不同的衰退类型。
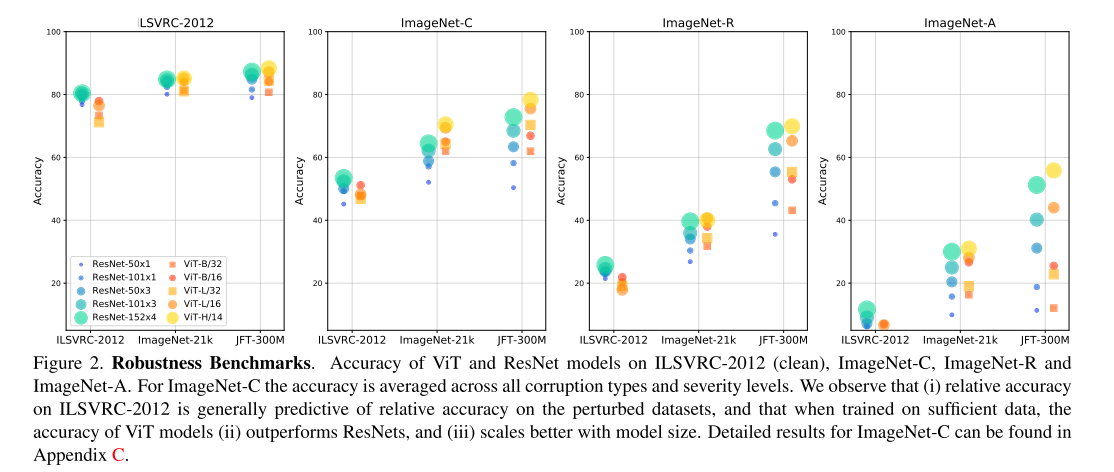
实验结果为上图第二列,从图中可以看出:在数据集较小时, ViT 的鲁棒性不如 ResNets,而随着数据集的逐渐增大,ViT的鲁棒性也逐渐超过 ResNets。
3.2 Real-world Distributation Shifts
用于测试的数据集:ImageNet-R
实验结果与 3.1 相同
3.3 Natural Adversarial Examples
3.4 Robustness and Model Size
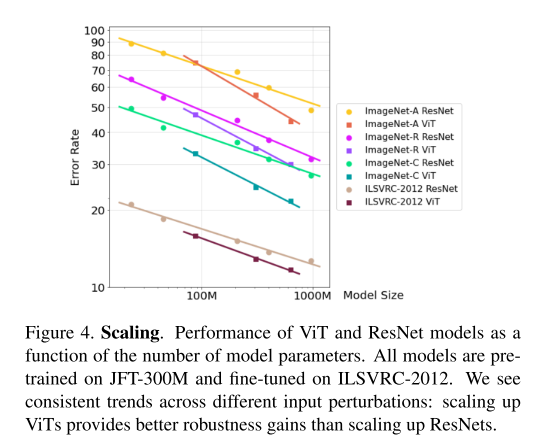
与 ResNet 相比,ViT 显示出更有利的伸缩性。这表明,给定一个足够大的训练前数据集,如 JFT-300M, ViT 和 ResNets 之间的鲁棒性差距将随着模型变得越来越大而进一步增大。
3.5 Adversarial Perturbations
对抗扰动: 对输入的扰动非常小,但经过精心设计,会导致模型产生不正确的预测。
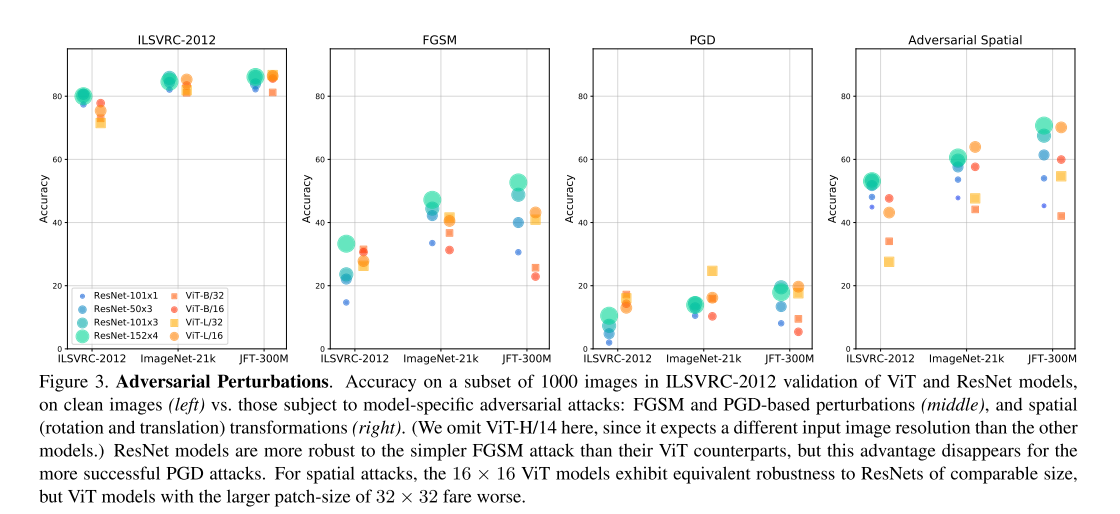
如上图所示,基于注意力机制的模型往往比其他结构(如循环网络)对此类扰动更有鲁棒性。

通过上图可知,所有的模型中,前景周围的像素受到的扰动幅度都是最大的;此外,对于ViT,pattern 与 patch partition 边界有明确的对齐。相反,ResNet 模型的 patterns 在空间上更不连贯。
3.6 Adversarial Spatial Perturbations
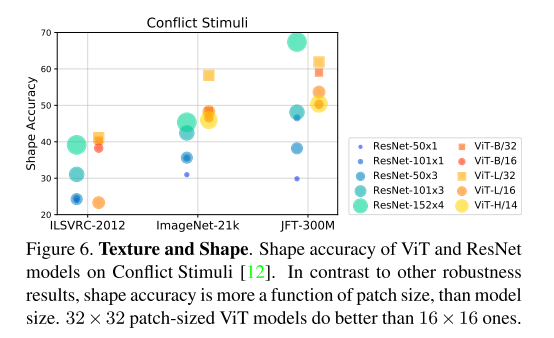
3.7 Texture Bias
- 经过imagenet训练的cnn更倾向于依赖纹理而不是形状来进行图像分类;减少纹理偏差可以提高对之前未见过的图像失真的鲁棒性。
- 较大的 patch 大小(32×32)的ViT模型比较小的 patch大小 (16 × 16)的变体性能更好;可能是因为较大的 patch 输入比较小的 patch 更能保持物体的形状。
4. Robustness to Model Perturbations
这一部分,作者通过计算 layer correlations, lesion studies and restricting attention 来理解 ViT 模型中的信息流
- Layer correlations
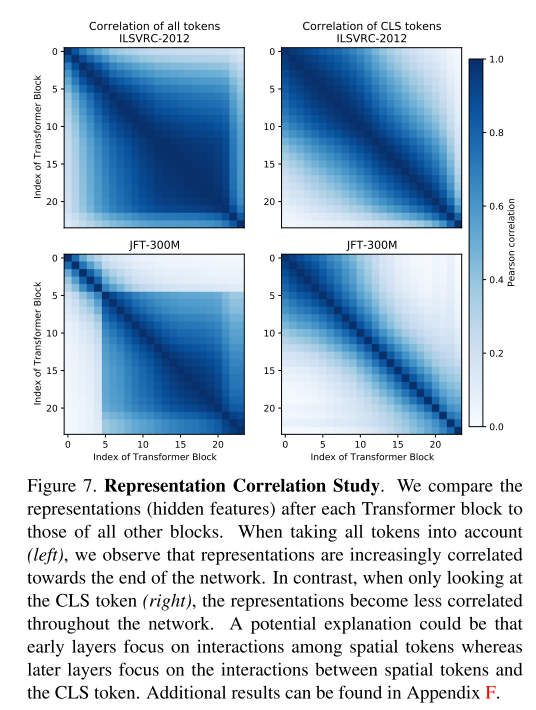
作者将每个 Transformer 块后的表示(hidden feature)与所有其他块的“表示”进行比较。当考虑到所有的 token 时(左),观察到“表示(representations)”越来越接近网络的末端。相反,当只看 CLS token 时(右边),“表示”在整个网络中变得不那么相关。一个可能的解释是,早期的层关注于空间 token 之间的交互,而后来的层关注于空间 token 和 CLS token 之间的交互。
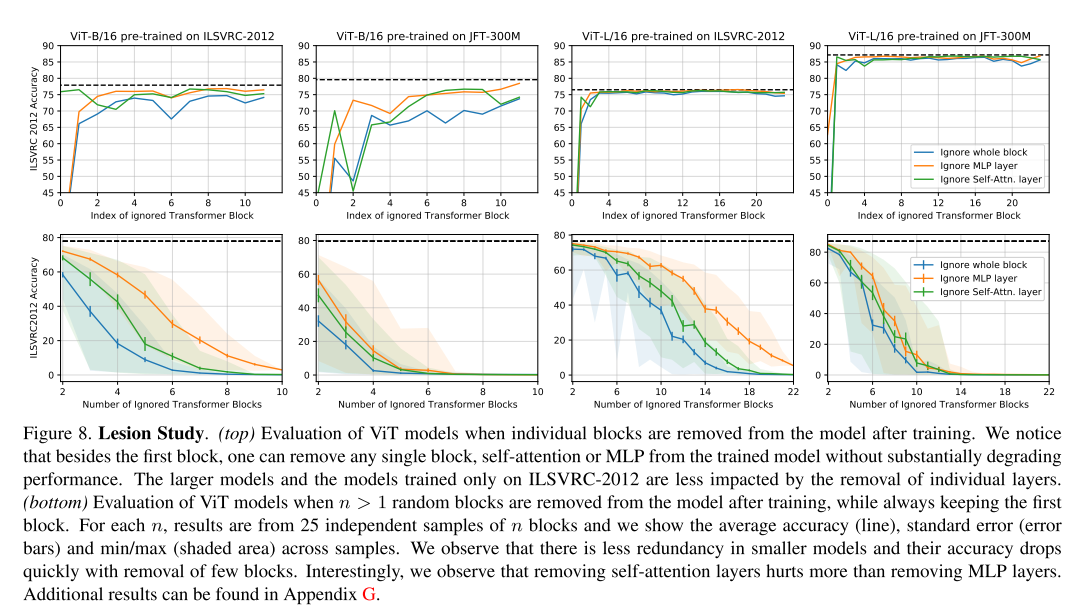
Lesion study
前人的研究表明,残差网络中的各层存在大量冗余,并且几乎可以在训练后去除任意一层而不影响性能,在 ViT 中也存在这种现象;
随着移除更多的层,性能逐渐恶化,越大的模型对移除层更有鲁棒性。作者还注意到,训练数据的数量也会影响鲁棒性:在大型数据集上预训练的模型对去层的鲁棒性较差,这表明可能有更高的模型利用率。
结果进一步表明,去除单个层比去除完整块降低了精度,这表明在每个 Transformer 块内的组件之间存在有限的协同适应。
去除 MLP 层比去除相同数量的 self-attention 层对模型的伤害更小,表明了自我注意的相对重要性。
- Restricted attention
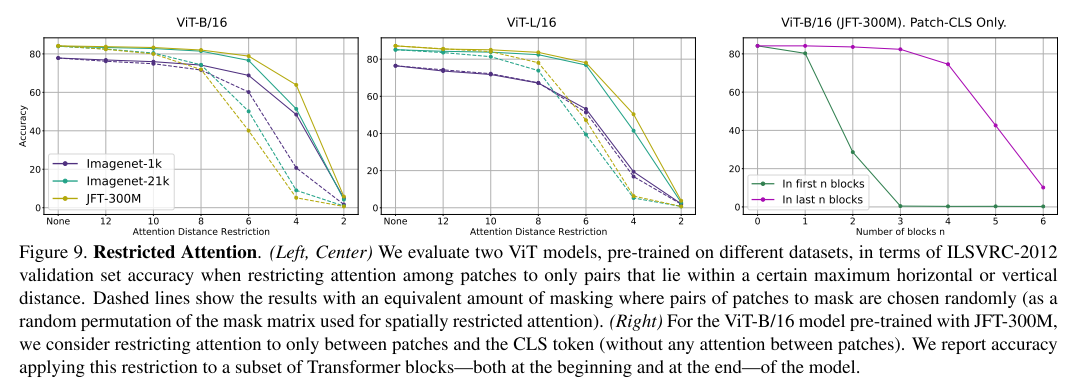
作者发现 ViT 模型包含惊人参数数量的冗余,这表明在推理过程中该模型可以被大量修剪。
5. Conclusion
- 在足够的数据上训练时,ViT 模型的准确性优于 ResNets
- 随着模型大小的增加,Transformer更好地缩放
- 较小的patch-size (16×16) ViT模型并不比ResNets模型更容易受到影响,但较大的patch-size (32 × 32) ViT模型更容易受到影响
- 发现32×32 ViT模型比16 × 16的模型有更少的纹理偏差
- 应用对抗空间扰动时,我们发现较小的patch-size (16×16) ViT模型并不比ResNets模型更容易受到影响,但较大的patch-size (32 × 32) ViT模型更容易受到影响。
- 发现32×32 ViT模型比16 × 16的模型有更少的纹理偏差